



Spring 들어가기 전 자바 나만의 정리
원시타입
더보기
1. 논리형 변수 : boolean
2. 문자형 변수 : char
3. 정수형 변수 : byte, short , int, long
4.실수형 변수 : float, long
참조타입
더보기
참조타입은 원시 타입을 제외한 타입들(문자열, 배열, 열거, 클래스, 인터페이스)를 말한다
ex)
1.문자열 변수 : String
2.그 외 : Object, Array, List.....
Wrapper Class
더보기
래퍼 클래스는 하나 이상의 기본 타입(primitive type)을 wrap 하는 클래스입니다.
- 박싱 VS 언박싱
- 기본 타입에서 래퍼 클래스 변수로 변수를 감싸는 것을 “박싱”이라고 부르며
- 래퍼 클래스 변수를 기본 타입 변수로 가져오는 것을 “언박싱”이라고 부릅니다.
문자와 문자열의 차이
더보기
char 문자 한개만 / 문자 뒤에 \0(널문자) 가 없다 (byte 만 쓰기 때문에 끝을 알아서 데이터만 저장하면 됨
String 문자 여러개를 문장형태로 저장 / 문장 끝에 \0(널문자)가 함께 저장된다.
메모리 구조(Heap, Stack, Method)
더보기
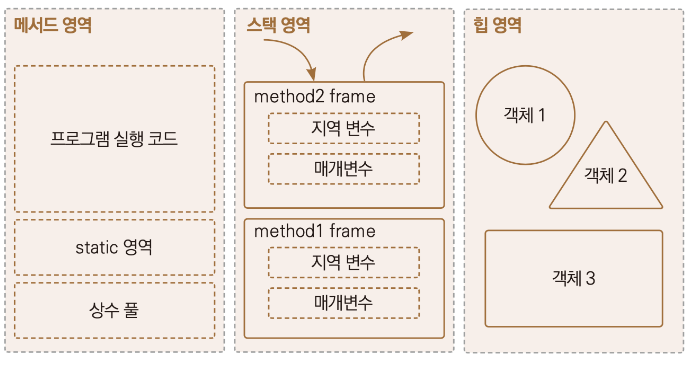
1. 변수의 종류
| 변수명 | 선언위치 | 설명 |
| 클래스 변수 (static 변수) |
클래스 영역 | 클래스 영역에서 타입 앞에 static이 붙는 변수 객체를 공유하는 변수로 여러 객체에서 공통으로 사용하고 싶을 때 정의 |
| 인스턴스 변수 (instance variable) |
클래스 영역에서 static이 아닌 변수 개별적인 저장 공간으로 객체/인스턴스마다 다른 값 저장 가능 ※객체 / 인스턴스 생성만 하고 참조 변수가 없는 경우 가비지 컬렉터에 의해 자동으로 제거됨 |
|
| 지역 변수 (local variable) |
메서드 영역 | 메서드 내에서 선언되고 메서드 수행이 끝나면 소멸되는 변수 초깃값을 지정한 후 사용할 수 있음 |
| 매개 변수 (parameter) |
메서드 호출 시 '전달하는 값'을 가지고 있는 인수 (지역 변수처럼 선언된 곳부터 수행이 끝날 때까지 유효함) |
1. method 영역
- JVM이 동작해서 클래스가 로딩될 때 생성
- JVM이 읽어들인 클래스와 인터페이스에 대한 런타임 상수 풀, 멤버 변수(필드). 클래스 변수, 상수,
생성자와 메서드 등을 저장하는 공간 - Method(Static) 영역에 있는 것은 어는곳에서나 접근 가능
- Methd(static)영역의 데이터는 프로그램의 시작부터 종료가 될 때까지 메모리에 남아있다.
2. Stack 영역 (정적으로 할당된 메모리 영역)
- 메서드 내에서 정의하는 기본 자료형에 해당되는 지역변수의 데이터 값이 저장되는 공간
- 메서드가 호출될때 스택 영역에 스택 프레임이 생기고 그안에 메서드를 호출
- 원시 타입의 데이터에 해당하는 지역변수, 매개 변수 데이터 값이 저장
- 메서드가 호출 될 때 메모리에 할당되고 종료되면 메모리에서 사라짐
- Stack은 후입선출 LIFO(Last - In - First - Out)의 특성을 가지며, 스코프(Scope)의 범위를 벗어나면
스택 메모리에서 사라진다.
3. Heap 영역 (동적으로 할당된 메모리 영역)
- JVM이 관리하는 프로그램 상에서 데이터를 저장하기 위해 런타임 시 동적으로 할당하여 사용하는 영역
- 참조 데이터 타입을 갖는 객체(인스턴스), 배열 등이 저장 되는 공간
- 단 ,Heap 영역에 있는 오브젝트들을 가리키는 레퍼런스 변수는 stack에 적재
- Heap 영역은 Stack 영역과 다르게 보관되는 메모리가 호출이 끝나더라도 삭제되지 않고 유지된다.
그러다 어떤 참조 변수도 Heap 영역에 있는 인스턴스를 참조하지 않게 된다면, GC(가비지 컬렉터)에 의해
메모리에서 청소된다. - stack은 스레드 갯수마다 각각 생성되지만, heap은 몇개의 스레드가 존재하든 상관없이
단 하나의 heap 영역만 존재
형변환
더보기
자동 형변환 vs 강제 형변환
- 작은 타입 -> 큰 타입 (자동 형변환)
- 더 큰 표현범위를 가진 타입으로 변환되는 것이라 값의 손실이 없다.
- 값의 손실없이 변환이 가능하기 때문에 컴파일러가 자동으로 형변환을 해줍니다.
- 큰 타입 -> 작은 타입 (강제 형변환 = Casting)
- 더 작은 표현범위를 가진 타입으로 변환되는 것이라 손실이 생깁니다.
- 값의 손실이 생기기 댸문에 자동으로 형변환을 해주지 않고 개발자가 선택하여 형변환을 합니다.
배열
더보기
- 배열은 하나의 블록안에 여러 데이터들을 모아 집합시켜 저장함으로써 데이터를 구조적으로 다루는데 도와줌
- 배열을 구성하는 각각의 값을 배열 요쇼(element)라고한다
- 배열에서의 위치를 가리키는 숫자를 인덱스(index)라고 칭한다.
- 선언 방법
- 타입 [] 변수;
- 타입 변수[];
- 배열 / 얕은 복사 & 깊은 복사
- 얕은 복사
- 배열 변수 간에 대입 연산자 =를 사용해서 복사를 하게 되면 주소값만 복사된다.
- 이렇게 주소값만 복사되고 실제 값은 1개로 유지되는 것을 얕은 복사라고 한다.
- 깊은 복사
- 실제 값을 가지고 있는 배열의 기본형 값을 꺼내서 복사해 주면 된다.
- 반복문 for문을 통해서 하나씩 거내서 복사해 주는 방법과 여러 메서드를 사용하는 방법이 있다
- 반복문 for문을 통해서 하나씩 거내서 복사해 주는 방법과 여러 메서드를 사용하는 방법이 있다
- 실제 값을 가지고 있는 배열의 기본형 값을 꺼내서 복사해 주면 된다.
- 얕은 복사
- 다차원 배열

- 선언
- 2차원 배열을 선언할 때는 1차원 배열에 대괄호 하나 더 추가해 주면 된다.
- int[][] array, int arrat[][], int[] array[]
- 선언
컬렉션 (Queue, Stack, List, Map)
더보기
- Java에서 컬렉션은 배열보다 다수의 참조형 데이터를 더 쉽고 효과적으로 처리할 수 있는 기능을 많이 가진다.
- 기능 : 크기 자동 조정/ 추가/ 수정/ 삭제/ 반복/ 순회/ 필터/ 포함 확인 등….
- 종류
- List : 순서가 있는 데이터의 집합(데이터 중복 허용)
- Set : 순서가 없는 데이터의 집합(데이터 중복 허용 안함)
- Queue : 빨대처럼 한쪽에서 데이터를 넣고 반대쪽에서 데이터를 뺄 수 있는 집합
First In First Out : 먼저 들어간 순서대로 값을 조회할 수 있다. - Map : 순서가 없는 (Key, Value) 쌍으로 이루어진 데이터의 집합 (Key값 중복 허용 안 함)
- List
- ArrayList (일렬로 데이터를 저장, 조회하여 순번 값(인덱스)로 값을 하나씩 조회)
- 배열처럼 일렬로 데이터를 저장하고 조회하여 순번 값(인덱스)로 값을 하나씩 조회할 수 있다
- add() 값을 추가, set() 값을 수정, remove() 값을 삭제,toString() 전체 값을 대괄호[]로 묶어서 출력
- LinkedList ( 값을 중간에 추가하거나 삭제할 때는 속도가 빠르다)
- 메모리에 남는 공간을 요청해서 여기저기 나누어서 실제 값을 담아 놓고, 실제 값이 있는
주소값으로 목록을 구성하고 저장 - add() 값을 추가, add({추가할 순번}, {추가할 값}) 값을 중간에 추가
set({수정할 순번}, {수정할 값}) 값을 수정, remove() 값을 삭제
- 메모리에 남는 공간을 요청해서 여기저기 나누어서 실제 값을 담아 놓고, 실제 값이 있는
- ArrayList (일렬로 데이터를 저장, 조회하여 순번 값(인덱스)로 값을 하나씩 조회)
- Stack
- 값을 수직으로 쌓아놓고 넣었다가 빼서 조회하는 형식으로 데이터를 관리 (Last-In-First-out)
- push({추가할 값}) 값을 추가, peek() 맨 위값을 조회, pop() 맨 위값을 꺼냄 (꺼내고 나면 삭제됨)
- Queue
- 한쪽에서 데이터를 넣고 반대쪽에서 데이터를 뺄 수 있는 집합( First In First Out)
- Queue는 생성자가 없음( LinkedList를 사용하여 Queue를 생성해서 받을 수 있다)
- add({추가할 값}) 값을 맨 위에 추가, peek() 맨 아래 값을 조회 poll() 맨 아래 값을 꺼냄. (꺼낸 후 삭제)
- Set
- 순서가 없는 데이터의 집합 (데이터 중복 허용 안 함) - 순서 없고 중복 없는 배열
- Set은 생성자가 없음 (HashSet를 사용하여 Set를 생성해서 받을 수 있다)
- add({추가할 값}) 값을 맨 위에 추가, contains({포함 확인 할 값}) 해당 값이 포함되어있는지
boolean 값으로 응답
- Map
- Map 은 key-value 구조로 구성된 데이터를 저장할 수 있다
- key-value 형태로 데이터를 저장하기 때문에 기존에 순번으로만 조회하던 방식에서, key 값을 기준으로 vlaue를 조회할 수 있다.
- put({추가할 Key값},{추가할 Value값}) Key에 Value값을 추가
get({조회할 Key값}) Key에 있는 Value값을 조회
keySet() 전체 key 값들을 조회
values() 전체 value 값들을 조회
remove({삭제할 Key값}) Key에 있는 Value값을 삭제
.charAt()
더보기
CahrAt()은 String 문자열 중 한 글자만 선택해서 Char타입으로 변환해준다.
char asciiNumber = sc.next().charAt(0);
int ch = (int) asciiNumber;
.to String
더보기
toString 메서드는 객체가 가지고 있는 정보나 값들을 문자열로 만들어 리턴하는 메서드입니다.
int[] arr = {1,2,3,4};
System.out.println(Arrays.toString);
//출력 결과 = [1,2,3,4]객체
더보기
- 객체
- 객체는 클래스에 의해 정의되고 설계된 내용을 기반으로 생성.
- 객체는 속성과 행위를 가진다
- 객체의 속성은 필드(변수), 행위는 메서드에 해당한다.
- 클래스를 통해 생성된 객체를 클래스의 인스턴스(instance)라 부른다.
- -캡슐화
- 속성(필드)와 행위(메서드)를 하나로 묶어 객체로 만든 후 실제 내부 구현 내용은 외부에서 알 수 없게 감추는 것을 의미
- 외부 객체에서 해당 필드와 메서드를 잘못 사용하여 객체가 변화하지 않게 하는 데 있다.
- 캡슐화된 객체의 필드와 메서드를 노출시킬지 감출지 결정하기 위해 접근 제어자를 사용
클래스 설계
더보기
- 만들려고 하는 설계도를 선언합니다.(클래스 선언)
- 객체가 가지고 있어야 할 속성(필드)을 정의합니다.
- 객체를 생성하는 방식을 정의합니다.(생성자)
- 객체가 가지고 있어야 할 행위(메서드)를 정의합니다.
- 객체 생성
- 객체 생성 연산자인 ‘new’를 사용하면 클래스로부터 객체를 생성할 수 있다.
- new 연산자 뒤에는 해당 클래스의 생성자 호출 코드를 작성
- 참조형 변수
- new 연산자를 통해서 객체가 생성되면 해당 인스턴스의 주소가 반환되기 때문에 해당 클래스의
참조형 변수를 사용하여 받아줄 수 있다.
- new 연산자를 통해서 객체가 생성되면 해당 인스턴스의 주소가 반환되기 때문에 해당 클래스의
- 객체 배열
- 객체는 참조형 변수와 동일하게 취급되기 때문에 배열 또는 컬렉션에도 저장하여 관리할 수 있다.
필드 사용법
더보기
- 필드란?
- 객체의 데이터를 저장하는 역할
- 필드는 크게 고유한 데이터, 상태 데이터, 객체 데이터로 분류
- 필드들은 기본적으로 초기값을 제공하지 않을 경우 객체가 생성될 때 자동으로 기본값으로 초기화 된다.
- 필드 사용 방법
- 외부 접근
- ex) Car car = new Car();
- 객체를 생성했다면 참조 변수 car를 이용하여 외부에서 객체 내부의 필드에 접근하여 사용할 수 있다.
- 객체 내부 필드에 접근하는 방법은 도트(.)연산자를 사용하면 된다.
- 내부 접근
- 도트 연산자를 사용하여 외부에서 객체 내부에 접근할 수 있을 뿐만 아니라 객체 내부 메서드에서도
내부 필드에 접근할 수 있다.
- 도트 연산자를 사용하여 외부에서 객체 내부에 접근할 수 있을 뿐만 아니라 객체 내부 메서드에서도
- 외부 접근
메서드 선언 & 리턴타입
더보기
- 메서드
- 메서드는 객체의 행위를 듯하며 객체 간의 협력을 위해 사용된다.
- 메서드의 행위를 정의하는 방법은 블록{ } 내부에 실행할 행위를 정의하면 된다.
- 리턴 타입
- 메서드가 실행된 후 호출을 한 곳으로 값을 반환할 때 해당 값의 타입을 의미
- return 리턴 타입의 반환값;
- 메서드에 리턴 타입을 선언하여 반환할 값이 있다면 반드시 return 문으로 해당하는 리턴 타입의 반환값을 지정
- 반환할 값이 없을 때는 리턴 타입에 void를 작성
- 반환값이 없음으로 return문을 반드시 지정할 필요는 없다.
- 메서드가 실행된 후 호출을 한 곳으로 값을 반환할 때 해당 값의 타입을 의미
- 메서드 호출 방법
- 외부 접근
- ex) Car car = new Car();
- 참조 변수 car를 이용하여 외부에서 객체 내부의 메서드에 접근하여 호출
- 객체의 내부 메서드에 접근하는 방법은 도트(.) 연산자를 사용
- 내부 접근
- 객체 내부 메서드에서도 내부 메서드에 접근하여 호출할 수 있다
- 객체 내부 메서드에서도 내부 메서드에 접근하여 호출할 수 있다
- 외부 접근
- 메서드 오버로딩
- 함수가 하나의 기능만을 구현하는 것이 아니라 하나의 메서드 이름으로
여러 기능을 구현하도록 하는 Java의 기능 - 조건
- 메서드의 이름이 같고, 매개변수의 개수, 타입, 순서가 달라야 한다.
- '응답 값만' 다른 것은 오버로딩을 할 수 없다.
- 접근 제어자만 다른 것도 오버로딩을 할 수 없다.
- 오버로딩은 매개변수의 차이로만 구현할 수 있다.
- 장점
- 메서드 이름 하나로 상황에 따른 동작을 개별로 정의할 수 있다
- 메서드의 이름을 절약할 수 있다.
- 함수가 하나의 기능만을 구현하는 것이 아니라 하나의 메서드 이름으로
기본형&참조형 매개변수
더보기
- 기본형 매개변수
- 메서드를 호출할 때 전달할 매개값으로 지정한 값을 메서드의 매개변수에 복사해서 전달
- 매개 변수 타입이 기본형 / 값 자체가 복사되어 넘어가기 때문에 매개 값으로 지정된 변수의 원본 값 변경X
- 참조형 매개변수
- 메서드를 호출하 ㄹ때 전달할 매개값으로 지정한 값의 주소를 매개변수에 복사해서 전달
- 매개 변수를 참조형으로 선언하면 값이 저장된 곳의 원본 주소를 알 수 있기 대문에 값을
읽어 오는 것은 물론 값을 변경하는 것도 가능
인스턴스 멤버와 클래스 멤버
더보기
- 멤버 = 필드 + 메서드
- 인스턴스 멤버 = 인스턴스 필드 + 인스턴스 메서드
- 필드와 메서드는 선언하는 방법에 따라서 인스턴스 멤버와 클래스 멤버로 구분할 수 있다
- 인스턴스 멤버는 객체를 생성해야 사용할 수 있다
- 체의 인스턴스 필드는 각각의 인스턴스마다 고유하게 값을 가질 수 있다.
- 클래스 멤버 = 클래스 필드 + 클래스 메서드
- 인스턴스 멤버는 객체 생성 후에 사용할 수 있고 클래스 멤버는 객체 생성 없이도 사용할 수 있다
- 클래스는 Java의 클래스 로더에 의해 메서드 영역에 저장되고 사용
- 메서드 영역의 클래스와 같은 위치에 고정적으로 위치하고 있는 멤버를 의미
- 클래스 멤버는 객체의 생성 필요 없이 바로 사용이 가능
- 클래스 멤버 선언
- 필드와 메서드를 클래스 멤버로 만들기 위해서는 static 키워드를 사용하면 된다.
지역변수
더보기
- 메서드 내부에 선언한 변수를 의미
- 메서드가 실행될 때마다 독립적인 값을 저장하고 관리하게 된다.
- 지역 변수는 메서드 내부에서 정의될 때 생성되어 메서드가 종료될 때까지만 유지
final 필드와 상수
더보기
- final 필드는 초기값이 저장되면 해당값을 프로그램이 실행하는 도중에는 절대로 수정할 수 없다.
- final 필드는 반드시 초기값을 지정해야 한다
- final 선언
- 필드 타입 앞에 final 키워드를 추가하여 final 필드를 선언할 수 있다.
- 사용방법은 일반적인 인스턴스 필드와 동일합니다. 다만 수정이 불가능
- 상수
- 상수의 특징은 값이 반드시 한 개이며 불변의 값을 의미
- 인스턴스마다 상수를 저장할 필요가 없다.
- final 앞에 static 키워드를 추가하여 모든 인스턴스가 공유할 수 있는 값이 한 개이며
불변인 상수를 선언할 수 있다 - 사용방법은 일반적인 클래스 필드와 동일합니다. 다만 수정이 불가능
생성자
더보기
- 생성자는 객체가 생성될 때 호출되며 객체를 초기화하는 역할을 수행
- 생성자는 반환 타입이 없고 이름은 클래스의 이름과 동일
- new 연산자에 의해 객체가 생성
- 기본 생성자
- 기본 생성자는 선언할 때 괄호( ) 안에 아무것도 넣지 않는 생성자를 의미
- 모든 클래스는 반드시 생성자가 하나 이상 존재
- 선언하지 않았으면 컴파일러는 기본 생성자를 바이트코드 파일에 자동으로 추가
- 필드 초기화
- 생성자는 객체를 초기화하는 역할을 수행
- 객체를 만들 때 인스턴스마다 다른 값을 가져야 한다면 생성자를 통해서 필드를 초기화할 수 있다
this와 this()
더보기
- this
- this는 객체 즉, 인스턴스 자신을 표현하는 키워드
- 객체 내부 생성자 및 메서드에서 객체 내부 멤버에 접근하기 위해 사용될 수 있다.
- 객체 내부 멤버에 접근할 때 this 키워드가 필수는 아니지만 상황에 따라 필수가 될 수 있다
- this는 인스턴스 자신을 뜻하기 때문에 객체의 메서드에서 리턴 타입이
인스턴스 자신의 클래스 타입이라면 this를 사용하여 인스턴스 자신의 주소를 반환할 수도 있다
- this()
- this(…)는 객체 즉, 인스턴스 자신의 생성자를 호출하는 키워드
- 객체 내부 생성자 및 메서드에서 해당 객체의 생성자를 호출하기 위해 사용될 수 있다.
- 생성자를 통해 객체의 필드를 초기화할 때 중복되는 코드를 줄여줄 수 있다.
접근 제어자
더보기
- 제어자는 클래스, 변수, 메서드의 선언부에 사용되어 부가적인 의미를 부여해 준다
- 접근 제어자 : public, protected, default, private
- 그 외 제어자 : static, final, abstract
- 접근 제어자
- public : 접근 제한이 전혀 없습니다.
- protected : 같은 패키지 내에서, 다른 패키지의 자손 클래스에서 접근이 가능
- default : 같은 패키지 내에서만 접근이 가능
- private : 같은 클래스 내에서만 접근이 가능
- getter와 setter
- 객체의 무결성 즉, 변경이 없는 상태를 유지하기 위해 접근 제어자를 사용
- getter
- 외부에서 객체의 private 한 필드를 읽을 필요가 있을 때 Getter 메서드를 사용
- setter
- 외부에서 객체의 private 한 필드를 저장/수정할 필요가 있을 때 Setter 메서드를 사용
상속(extends)
더보기
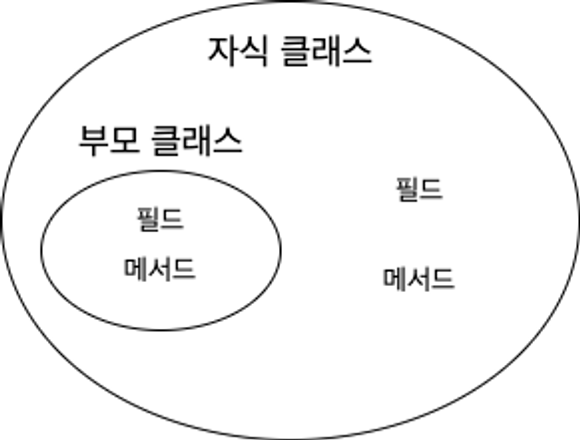
상속의 사전적 정의 : 부모가 자식에게 물려주는 행위
- 부모 클래스(필드, 메서드) -> 자식 클래스에게 물려줌
- 적은 양의 코드로 새로운 클래스를 작성할 수도 있고 공통적인 코드를 관리하여 코드의 추가와 변경이 쉬움
- 상속을 사용하면 코드의 중복이 제거되고 재사용성이 크게 증가하여 생산성과 유지 보수성에 매우 유리
1. 부모 클래스에 새로운 필드와 메서드가 추가되면 자식 클래스는 이를 상속받아 사용할 수 있다.
2. 자식 클래스에 새로운 필드와 메서드가 추가 되어도 부모 클래스는 어떠한 영향도 받지 않는다.
3. 자식 클래스의 멤버 개수는 부모 클래스보다 항상 같거나 많다
클래스 간의 관계
- 상속 관계 : is ~a ("~은 ~(이)다.")
- 포함 관계 : has ~a ("~은 ~을(를) 가지고 있다")
final 클래스와 final 메서드
- final 클래스
- 클래스에 final 키워드를 지정하여 선언하면 최종적인 클래스가 됨으로 더 이상 상속할 수 없는 클래스가 됨
- final 메서드
- 메서드에 final 키워드를 지정하여 선언하면 최종적인 메서드가 됨으로 더 이상 오버라이딩할 수 없는 메서드가 된다.
Object
더보기
Object clone() : 해당 객체의 복제본을 생성하여 반환
boolean equals(Object object) : 해당 객체와 전달받은 객체가 같은지 여부를 반환
Class getClass() : 해당 객체의 클래스 타입을 반환
int hashCode() : 자바에서 객체를 식별하는 정수값인 해시 코드를 반환
String toString() : 해당 객체의 정보를 문자열로 반환 & Object 클래스에서는 클래스의 이름 @해쉬코드값 리턴
...
오버라이딩
더보기
부모 클래스로부터 상속받은 메서드의 내용을 재정의 하는 것
- 부모 클래스의 메서드를 그대로 사용 가능 / 자식 클래스의 상황에 맞게 변경을 하는 경우 오버라이딩 사용
- 오버라이딩 조건
- 선언부가 부모 클래스와 일치해야 한다
- 접근 제어자를 부모 클래스의 메서드 보다 좁은 범위로 변경할 수 없다.
- 예외는 부모 클래스의 메서드 보다 많이 선언할 수 없다.
super & super()
super
- 부모 클래스의 멤버를 참조할 수 있는 키워드
- 객체 내무 생성자 및 메서드에서 부모 클래스의 멤버에 접간하기 위해 사용
- 자식 클래스 내부에서 선언한 멤버와 부모 클래스에서 상속받은 멤버와 이름이 같은 경우
이를 구분하기 위해 사용
super()
- super(...)는 부모 클래스의 생성자를 호출할 수 있는 키워드
- 객체 내부 생성자 및 메서드에서 해당 객체의 부모 클래스의 생성자를 호출하기 위해 사용
- 자식 클래스의 객체가 생성될 때 부모 클래스들이 모두 합쳐져서 하나의 인스턴스가 생성
다형성
더보기
참조 변수의 타입 변환
- 자동 타입 변환
- 부모 타입 변수 = 자식 타입 객체; 는 자동으로 부모 타입으로 변환이 일어난다,
- 자식 객체는 무보 객체의 멤버를 상속받기 때문에 부모와 동일하게 취급될 수 있다.
- 강제 타입 변환
- 자식 타입 변수 = (자식 타입) 부모 타입 객체;
- 부모 타입 객체는 자식 타입 변수로 자동으로 타입 변환되지 않는다.
다형성이란?
- 여러 가지 형태를 가질 수 있는 능력을 의미
instanceof
- 다형성 기능으로 인해 해당 클래스 객체의 원래 클래스명을 체크하는 것이 필요한데 이때 사용할 수 있는
명령어가 instanac of 이다.- 해당 객체가 내가 의도하는 클래스의 객체인지 확인할 수 있다
- {대상 객체} instance of {클래스 이름} / 응답값은 boolean
추상 클래스
더보기
- 추상 클래스란?
- 클래스가 설계도라면 추상 클래스는 미완성된 설계도
- abstarct 키워드를 사용하여 추상 클래스를 선언할 수 있다.
- 추상 클래슨느 추상 메서드를 포함할 수있다 (추상 메서드 없어도 추상 클래스 선언 가능)
- 추상 클래스는 자식 클래스에 상속되어 자식 클래스에 의해서만 완성될 수 있습니다.
- 추상 클래스는 여러 개의 자식 클래스들에서 공통적인 필드나 메서드를 추출해서 만들 수 있다.
- 추상 메서드
- 추상 메서드는 아직 구현되지 않은 미완성된 메서드
- abstarct 키워드를 사용하여 추상 메서드를 선언할 수 있다.
- 추상 메서드는 일반적인 메서드와는 다르게 블록{} 이 없다.(정의만 할 뿐, 실행 내용은 가지고 있지 않음)
- 추상 메서드는 extends 키워드를 사용하여 클래스에 상속
- 상속받은 클레스에서 추상 클래스에서 추상 메서드는 반드시 오버라이딩 되어야 한다.
인터페이스
더보기
- 인터페이스는 두 객체를 연결해 주는 다리 역할을 한다.
- 상속 관계가 없는 다른 클래스들이 서로 동일한 행위, 메서드를 구현해야 할 때 인터피에스는 구현 클래스들의
동일한 사용 방법과 행위를 보장해 줄 수 있다.
- 인터페이스 선언
- interface 키워드를 사용하여 인터페이스를 선언할 수 있다. (public, default 접근 제어자 지정 가능)
- 인터페이스 구성
- 인터페이스의 모든 멤버 변수는 public static final이어야 한다(생략 가능)
- 모든 메서드는 public abstract이어야 한다(생략 가능)
- 생략되는 제어자는 컴파일러가 자동으로 추가한다.
- 인터페이스 구현
- 인터페이슨느 추상 클래스와 마찬가지로 직접 인스턴스를 생성할 수 없기 때문에 클래스에 구현되어 생성
- implements 키워드를 사용하여 인터페이스를 구현할 수 있다
- 인터페이스의 추상 메서드는 구현될 때 반드시 오버라이딩 되어야 한다.
- 만약 인터페이스의 추상 메서드를 일부만 구현해야 한다면 해당 클래스로 변경해 주면 된다.
- 인터페이슨느 추상 클래스와 마찬가지로 직접 인스턴스를 생성할 수 없기 때문에 클래스에 구현되어 생성
- 인터페이스 상속
- 인터페이스 간의 상속은 extends를 사용한다
- 인터페이스는 클래스와 다르게 다중 상속이 가능하다.
- 다형성
- 강제 타입 변환
- 구현 객체 타입 변수 = (구현 객체 타입) 인터페이스 변수;
- 구현 객체 타입 변수 = (구현 객체 타입) 인터페이스 변수;
- 자동 타입 변환
- 인터페이스 변수 = 구현 객체; 자동으로 타입 변환
- 강제 타입 변환
디폴트 메서드와 static 메서드
더보기
- 디폴트 메서드는 추상 메서드의 기본적인 구현을 제공하는 메서드이다.
- 메서드 앞에 default 키워드를 붙이며 블럭{} 이 존재해야 한다.
- default 메서드 역시 접근 제어자가 public이며 생략이 가능하다.
- 추상 메서드가 아니기 때문에 인터페이스의 구현체들에서 필수로 재정의 할 필요는 없다
- static 메서드는 인터페이스에서 static 선언이 가능하다.
- static의 특성 그대로 인터페이스의 static 메서드 또한 객체 없이 호출이 가능하다
- 선언하는 방법과 호출하는 방법은 클래스의 static 메서드와 동일.
오류 & 예외
더보기
- 오류(Error)는 일반적으로 회복이 불가능한 문제!
- 예외(Exception)는 일반적으로 회복이 가능한 문제!
- 예외의 종류
- 컴파일 에러(예외)
- .java 파일을 .class 파일로 컴파일할 때 발생하는 에러
- 자바 프로그래밍 언어의 규칙을 지키지 않았기 때문에 발생
- 컴파일 에러가 발생하는 경우 해결 방법은 문법에 맞게 다시 작성하는 것
- 런타임 에러(예외)
- 주로 다루게 될 에러(예외)이다.
- 문법적인 오류는 아니라서, 컴파일은 잘 되었지만 "프로그램"이 실행 도중 맞닥뜨리게 되는 예외
- 컴파일 에러(예외)
- 예외처리 관점에서 예외의 종류
- 확인된 예외(Checked Exception)
- 컴파일 시점에 확인하는 예외이다
- 반드시 예외 처리를 해줘야 하는 예외
- 확인된 예외(Checked Exception)
- 예외 발생
- 클래스를 만들고, 메서드를 만들며 우리의 메서드가 위험하다고 알리기(throw, throws)
| throws | throw |
| 메서드 이름 뒤에 붙어 이 메서드가 어떠한 예외사항을 던질 수 있는지 알려주는 예약어입니다. | 메서드 안에서, 실제로 예외 객체를 던질 때 사용하는 예약어입니다. |
| 여러 종류의 예외사항을 적을 수 있습니다. | 실제로 던지는 예외 객체 하나와 같이 써야 합니다. |
| 일반 메서드의 return 키워드처럼 throw 아래의 구문들은 실행되지 않고, throw문과 함께 메서드가 종료됩니다. |
- try - cathch, finally
- try - catch 는 각각 중괄호{} 를 통해 실행할 코드들을 담는다.
- try {} 안에는 예외가 발생할 수 있지만 실행을 시도 할 코드를 담는다.
- catch{} 안에는 try 안에 있는 코드를 실행하다가 예외가 났을 때 실행할 코드를 담는다
- catch 는 소괄호()를 통해 어떤 예외 클래스를 받아서 처리할지 정의해 주어야 한다
- 기존 try - catch의 맨 마지막에 finally를 붙여서 마지막에 반드시 실행할 코드를 넣을 수 있습니다.
- Throwable Class
- 시작은 모든 객체의 원형인 Objcet 클래스에서 시작한다.
- Throable 클래스가 Object 클래스를 상속
- Throwable 클래스는 자식 클래스로 오류(Error)와 예외(Exception) 클래스가 있다.
- Chained Eception
- 예외는 다른 예외를 유발할 수 있음
- 예외 A가 예외 B를 유발시켰다면 , 예외 A는 예외 B의 원인 예외이다.
- 원인 예외를 다루기 위한 메서드
- initCause() : 지정한 예외를 원인 예외로 등록하는 메서드
- getCuase() : 원인 예외를 반환하는 메서드
- 실질적 예외 처리 방법
- 예외 복구하기(try - catch)
- 예외 처리 회피
- 예외 전환 *
제네릭
더보기
- 제네릭?
- 타입 언어에서 중복되거나 필요 없는 코드를 줄여주는 것
- 타입 안정성
- 제네릭 용어
- 제네릭을 사용한 클래스를 제네릭 클래스라고 한다.
- 제네릭에서 <> 사이에 들어가는 변수명은 타입 변수라고 한다,
- Generic 클리스를 원시 타입이라고 한다
- 제네릭의 제한
- 객체의 static 멤버를 사용할 수 없다
- 타입 변수는 인스턴스 변수로 간주되고, 모든 객체에 동일하게 동작해야 하는 static 필드 특성상
사용할 수 없다. - 제네릭 배열을 생성할 수 없다.
- 타입 변수는 인스턴스 변수로 간주되고, 모든 객체에 동일하게 동작해야 하는 static 필드 특성상
- 객체의 static 멤버를 사용할 수 없다
- 제네릭 문법
- 다수의 타입 변수를 사용할 수 있다.
- 다형성 즉 상속과 타입 관계는 그대로 적용
- 와일드카드를 통해 제네릭의 제한을 구체적으로 정할 수 있다.
- <? extends T> : T와 그 자손들만 사용 가능
- <? super T> : T와 그 조상들만 가능
- <?> : 제한 없음
프로세스와 쓰레드
더보기
- 프로세스 : 운영체제로부터 자원을 할당받는 작업의 단위
- 쓰레드 : 프로세스가 할당받은 자원을 이용하는 실행의 단위
- 프로세스 구조
- 프로세스를 할당해줄때 프로세스 안에서 프로그램 Code Data 그리고 메모리 영역(Heap, Stack) 할당
- 프로세스를 할당해줄때 프로세스 안에서 프로그램 Code Data 그리고 메모리 영역(Heap, Stack) 할당
- 쓰레드
- 프로세스 내에서 코드 실행의 흐름이라고 생각하면 된다.
- 쓰레드의 생성
- 프로세스가 작업중인 프로그램에서 실행요청이 들어오면 쓰레드를 만들어 명령을 처리하도록 한다.
- 쓰레드의 자원
- 프로세스 안에는 여려 쓰레드가 있고, 쓰레드는 실행을 위한 프로세스 내 주소공간이나 메모리 공간을
공유 받음 - 쓰레드는 각각 명령처리를 위한 자신만의 메모리공간(Stack)도 할당받음
- 프로세스 안에는 여려 쓰레드가 있고, 쓰레드는 실행을 위한 프로세스 내 주소공간이나 메모리 공간을
- 싱글 쓰레드
- 프로세스 안에서 하나의 쓰레드만 실행되는 것을 말한다.
- Java 프로그램 main() 메서드의 쓰레드를 '메인 쓰레드' 라고 부른다.
- 멀티 쓰레드
- 프로세스 안에서 여러 개의 쓰레드가 실행되는 것을 말한다
- 장점
- 여러 개의 쓰레드를 통해 여러 개의 작업을 동시에 할 수 있어서 성능이 좋아진다.
- 스택을 제외한 모든 영역에서 메로미를 공유하기 때문에 자원을 보다 효율적으로 사용할 수 있다.
- 응답 쓰레드와 작업 쓰레드를 분리하여 빠르게 응답을 줄 수 있다(비동기)
- 단점
- 동기화 문제가 발생할 수 있다.
- 교착 상태(데드락)이 발생할 수 있다.
- Runnable
- Runnable은 인터페이스이기 때문에 다른 필요한 클래스를 상속받을 수 있다.(확장성에 매우 유리)
- Runnable은 인터페이스이기 때문에 다른 필요한 클래스를 상속받을 수 있다.(확장성에 매우 유리)
- 데몬 쓰레드
- 보이지 않는 곳(Background) 에서 실행되는 낮은 우선순위를 가진 쓰레드를 말한다.
- 대표적으로 메모리 영역을 정리해 주는 가비지 컬렉터(GC)가 있다.
- 보이지 않는 곳(Background) 에서 실행되는 낮은 우선순위를 가진 쓰레드를 말한다.
- 사용자 쓰레드
- 보이는 곳(foreground)에서 실행되는 높은 우선 순위를 가진 스레드를 말한다.
- 프로그램의 기능을 담당 / 대표적으로 메인 쓰레드가 있다.
- 쓰레드 우선순위
- setPriority() 메서드로 우선순위를 설정할 수 있다.
- getPriority() 메서드로 우선순위를 반환하여 확인할 수 있다.
- 우선순위는 아래와 같이 3가지 (최대/최소/보통) 우선순위로 나뉩니다.
- 최대 우선순위 (MAX_PRIORITY) = 10
- 최소 우선순위 (MIN_PRIORITY) = 1
- 보통 우선순위 (NROM_PRIORITY) = 5
- 기본 값이 보통 우선순위입니다.
- 쓰레드 그룹
- 서로 관련이 있는 쓰레드들은 그룹으로 묶어서 다룰 수 있다.
- JVM이 시작되면 system 그룹이 생성되고 쓰레드들은 기본적으로 system 그룹에 포함
- 모든 쓰레드들은 반드시 하나의 그룹에 포함되어 있어야 합니다.
- 그룹을 지정하지 않으면 해당 쓰레드는 자동으로 main 그룹에 포함된다.
- 그룹을 지정하지 않으면 해당 쓰레드는 자동으로 main 그룹에 포함된다.
- 서로 관련이 있는 쓰레드들은 그룹으로 묶어서 다룰 수 있다.
- 쓰레드 상태
| 상태 | Enum | 설명 |
| 객체생성 | NEW | 쓰레드 객체 생성, 아직 start() 메서드 호출 전의 상태 |
| 실행대기 | RUNNABLE | 실행 상태로 언제든지 갈 수 있는 상태 |
| 일시정지 | WAITING | 다른 쓰레드가 통지할 때 까지 기다리는 상태 |
| 일시정지 | TIMED_WAITING | 주어진 시간 동안 기다리는 상태 |
| 일시정지 | BLOCKED | 사용하고자 하는 객체의 Lock이 풀릴 때까지 기다리는 상태 |
| 종료 | TERMINATED | 쓰레드의 작업이 종료된 상태 |
- 쓰레드 제어
- sleep(), interrupt()
- sleep() : 현재 쓰레드를 지정된 시간 동안 멈추게 한다(자기 자신만)
- interrupt() : 일시정지 상태인 쓰레드를 실행 대기 상태로 만든다.
- join(), yield()
- join() : 정해진 시간 동안 지정한 쓰레드가 작업하는 것을 기다린다.
- yield() : 남은 시간을 다음 쓰레드에게 양보하고 쓰레드 자신은 실행 대기 상태가 된다.
- synchronized
- 멀티 쓰레드의 경우 여러 쓰레드가 한 프로세스의 자원을 공유해서 작업하기 때문에 서로에게
영향을 줄 수 있다. 이로 인해 장애나 버그가 발생할 수 있음 - 다른 쓰레드가 침범하지 못하도록 막는 것을 '쓰레드 동기화(synchronized)' 라고 한다
- 멀티 쓰레드의 경우 여러 쓰레드가 한 프로세스의 자원을 공유해서 작업하기 때문에 서로에게
- wait(), notify()
- 침범을 막은 코드를 수행하다가 작업을 더 이상 진행할 상황이 아니면, wait()을 호출하여 쓰레드가
Lock을 반납하고 기다리게 할 수 있다. - 추후에 작업을 진행할 수 있는 상황이 되면 notify() 를 호출해서, 작업을 중단했던 쓰레드가 다시
Lock을 얻어 진행할 수 있게 된다. - wait() : 실행 중이던 쓰레드는 해당 객체의 대기실(waiting pool)에서 통지를 기다린다.
- notify() : 해당 객체의 대기실(waiting pool)에 있는 모든 쓰레드 중에서 임의의 쓰레드만 통지를 받는다.
- 침범을 막은 코드를 수행하다가 작업을 더 이상 진행할 상황이 아니면, wait()을 호출하여 쓰레드가
- Lock, Condition
- Lock : synchronized 블럭을 동기화하면 자동적으로 Lock이 걸리고 풀리지만, 같은 메서드 내에서만
Lock을 걸 수 있다는 제약이 있다.( 제약을 해결하기 위해 Lock 클래스를 사용한다)
- ReentrantLock (가장 일반적인 배타 Lock)
- ReentrantReadWriteLock (읽기 & 쓰기)
- StampedLock (낙관적인 Lock의 기능을 추가)
- Condition
- wait() & notify() 의 문제점인 waiting pool 내 쓰레드를 구분하지 못한다는 것을 해결한 것이
Condition 입니다.
- wait() & notify() 의 문제점인 waiting pool 내 쓰레드를 구분하지 못한다는 것을 해결한 것이
- Lock : synchronized 블럭을 동기화하면 자동적으로 Lock이 걸리고 풀리지만, 같은 메서드 내에서만
- sleep(), interrupt()
람다와 스트림
더보기
- 람다란?
- 익명 함수를 지칭하는 용어.
- 장점
- 코드의 간결성 - 람다를 사용하면 불필요한 반복문의 삭제가 가능하며 복잡한 식을 단순하게
표현할 수 있다. - 지연연산 수행 - 람다는 지연연상을 수행 함으로써 불필요한 연산을 최소화 할 수 있다.
- 병렬처리 가능 - 멀티 쓰레드를 활용하여 병렬처리를 사용할 수 있다.
- 코드의 간결성 - 람다를 사용하면 불필요한 반복문의 삭제가 가능하며 복잡한 식을 단순하게
- 단점
- 람다식의 호출이 까다롭다.
- 람다 stream 사용 시 단순 for문 혹은 while문 사용 시 성능이 떨어진다.
- 불필요하게 너무 사용하게 되면 오히려 가독성을 떨어 뜨릴 수 있다.
- 스트림
- 한 번 더 추상화 된 자료구조와 자주 사용하는 프로그래밍 API를 제공
- 특징
- 원본 데이터를 변경하지 않는다.
- 일회용이다.
'자바' 카테고리의 다른 글
| [TIL] 2024.08.14 [Java/Spring] (0) | 2024.08.16 |
|---|---|
| [TIL] 2024.08.13 [Java/Spring] (0) | 2024.08.13 |
| [TIL] 내일배움캠프 웹개발 백엔드 과정 2024.07.29 김현수 (0) | 2024.07.29 |
| [TIL] 내일배움캠프 웹개발 백엔드 과정 2024.07.26 김현수 (0) | 2024.07.26 |
| [TIL] 내일배움캠프 웹개발 백엔드 과정 2024.07.25 김현수 (0) | 2024.07.25 |